



Яндекс.XML — мощный инструмент для разработчиков и веб-мастеров, позволяющий получать доступ к данным поисковой системы Яндекс. Один из самых интересных и полезных функционалов, которые предлагает Яндекс.XML — это парсер сниппета.
В данной статье мы рассмотрим, как использовать Яндекс.XML и парсер сниппета на практике. Мы разберем, как получить доступ к API Яндекс.XML и как использовать его для получения сниппетов по вашим ключевым словам. Также рассмотрим, какие данные можно получить с помощью парсера сниппета и каким образом их можно использовать для оптимизации и продвижения страницы в поисковых системах.
Используем Яндекс.XML для оптимизации парсера сниппета поисковой системы Яндекс
Одним из таких инструментов является парсер сниппета. Сниппет – это краткое описание веб-страницы, которое отображается в результатах поиска. Парсер сниппета позволяет извлекать информацию из сниппетов поисковых систем и использовать ее для анализа и улучшения контента на своем сайте.
Яндекс.XML предоставляет разработчикам возможность получать доступ к результатам поиска Яндекса и извлекать из них информацию о сниппетах. При этом, можно указать различные параметры поиска (например, количество результатов, сортировку и др.), чтобы получить максимально релевантные данные.
Если вы хотите использовать Яндекс.XML для оптимизации парсера сниппета поисковой системы Яндекс, вам необходимо зарегистрироваться в сервисе и запросить у них ключ доступа. После этого вы сможете использовать API Яндекс.XML для отправки запросов на поиск и получения результатов в формате XML. Далее, вы можете анализировать полученные данные и использовать их для своих нужд – это может быть, например, оптимизация контента на вашем сайте или анализ позиций ваших конкурентов.
Использование Яндекс.XML для оптимизации парсера сниппета поисковой системы Яндекс – это один из способов получить доступ к данным Яндекса и использовать их в своих интересах. Это очень полезный инструмент для веб-мастеров и разработчиков, позволяющий улучшить качество контента на сайте и повысить его позиции в поисковой выдаче.
Что такое Яндекс.XML и как он может помочь в оптимизации?
Использование Яндекс.XML может значительно помочь в оптимизации сайта для поисковых систем. Один из самых значимых способов — это анализ данных о том, как именно Яндекс индексирует веб-страницы. Путем изучения этих данных можно оптимизировать заголовки, описания и ключевые слова страницы, чтобы сделать их более релевантными для поисковых запросов пользователей. Это позволяет улучшить позиции сайта в поисковой выдаче и увеличить его видимость.
Преимущества использования Яндекс.XML:

- Повышение видимости сайта: Анализ данных Яндекс.XML позволяет оптимизировать метаданные страницы и улучшить позиции сайта в поисковой выдаче.
- Улучшение качества трафика: Оптимизация страниц с помощью Яндекс.XML позволяет привлекать больше целевой аудитории, увеличивая релевантность сайта для конкретных поисковых запросов.
- Мониторинг индексации: Яндекс.XML предоставляет доступ к данным об индексации страниц, что позволяет контролировать и отслеживать процесс индексации в реальном времени.
- Оптимизация сниппетов: Яндекс.XML позволяет веб-мастерам настраивать вероятность отображения сниппетов страницы в поисковой выдаче, что увеличивает ее привлекательность для пользователей.
Настройка и использование Яндекс.XML для получения актуальных данных

Для настройки Яндекс.XML необходимо зарегистрироваться в сервисе, получить уникальный идентификатор и настроить параметры запроса. В параметрах запроса можно указать такие параметры, как язык, количество результатов, фильтрацию по дате и тематике. Правильная настройка параметров запроса позволяет получать наиболее актуальную информацию, соответствующую интересам пользователя.
Использование Яндекс.XML
После настройки Яндекс.XML можно приступить к его использованию для получения актуальных данных. Для этого необходимо отправить HTTP-запрос к серверу Яндекс.XML с указанием всех необходимых параметров. В ответ на запрос будет получена XML-структура, которая содержит информацию о страницах сайта, индексированных поисковой системой Яндекс.
Полученную XML-структуру можно обработать с помощью парсера и получить необходимые данные, такие как ссылка на страницу, заголовок, описание и дата индексации. Эти данные можно использовать для анализа позиций сайта в поисковой выдаче, определения релевантности сайта по ключевым словам и мониторинга актуальности информации.
Использование Яндекс.XML позволяет получать актуальные данные о страницах сайта, индексированных поисковой системой Яндекс, что помогает в анализе и оптимизации сайта для поисковых систем.
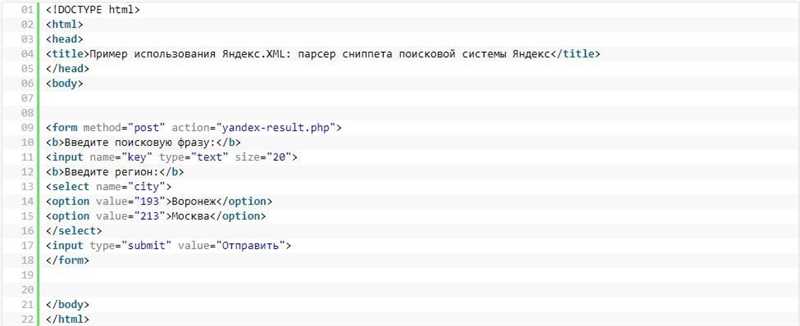
Пример использования Яндекс.XML в парсере сниппета Яндекса
Представим, что у нас есть парсер, который получает результаты поискового запроса из Яндекс.XML и извлекает необходимую информацию с технической выдачи. Для использования Яндекс.XML в парсере нам потребуется API-ключ, который мы можем получить на сайте Яндекс. После получения API-ключа, мы можем использовать его для отправки запросов к API Яндекс.XML.
Ниже приведен пример кода парсера на языке Python, который использует Яндекс.XML для получения сниппетов из поисковой выдачи Яндекса:
import requests
import xml.etree.ElementTree as ET
API_KEY = "your_api_key"
query = "example query"
url = "https://yandex.com/search/xml"
params = {
"key": API_KEY,
"user": "your_user_id",
"query": query,
"l10n": "ru",
"sortby": "rlv"
}
response = requests.get(url, params=params)
xml_data = ET.fromstring(response.content)
snippets = xml_data.findall(".//group[@mode='deep']/doc/snippet")
for snippet in snippets:
print(snippet.text)
Использование Яндекс.XML в парсере сниппета Яндекса позволяет получить больше информации о запросах, релевантности и позиции сайтов в выдаче поисковой системы Яндекс. Это открывает новые возможности для анализа и оптимизации поисковой оптимизации (SEO) сайтов. Кроме того, Яндекс.XML обеспечивает простой и удобный способ получения данных из выдачи Яндекса.